
自动定位问题、自动修复故障?托管云这个功能有点心动

用户业务应用增多,硬件性能跟不上?
云环境变得复杂,运维工作量不减反增?
运维人力成本日益激增,技术人才越招越少?
——信服云托管云的AIOps业务全生命周期持续性保障系统来啦!
帮助企业构建实时、持续的保障体系,覆盖业务全生命周期场景,以多层级时序监控对关键指标进行采集与观测,基于规则预测以及AI预测算法构建故障预测引擎。
同时,围绕业务全生命周期,建立基于AI技术的全栈预测,分析以及评估系统,完成问题自动定位和自动修复闭环,实现事先风险预防和主动规避,保障业务全生命周期的持续性。

业务全生命周期持续性保障系统能力概览
磁盘故障预测
通过智能采样,解决故障磁盘的样本不均衡问题,并解决时序依赖,自研小样本场景下基于深度学习的故障预测技术,捕捉相邻磁盘间的故障传播的模式,从而实现精准的磁盘故障预测。
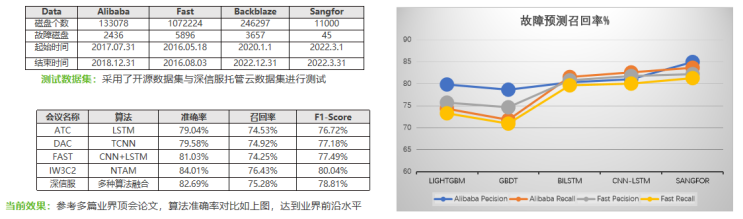
智能采样
内存ECC预测与隔离
内存ECC告警与隔离
大量CE报错会导致CE风暴,造成系统宕机,故需要对其先进行地址隔离,然后更换内存条,完成处置闭环。要想做到隔离地址的快速精确,最好是先对高风险CE地址的进行预隔离,进而做到内存条物理插槽快速定位,方便运维人员及时更换。另外,还需要采取持久化隔离,避免主机重启后隔离失效。
内存ECC预测
基于机器学习算法,系统对历史特征进行学习,并进行内存失效预测,提前预警,防患未然。其中主要包括基于CE特征预测CE风暴、UE等内存故障,基于内存性能、电压等指标评估DRAM健康状况,使预测结果更准确,降低误报导致的物料浪费,预测周期1-2小时。
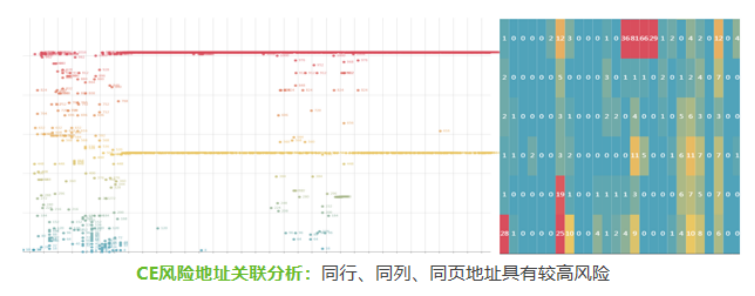
CE风险地址关联分析
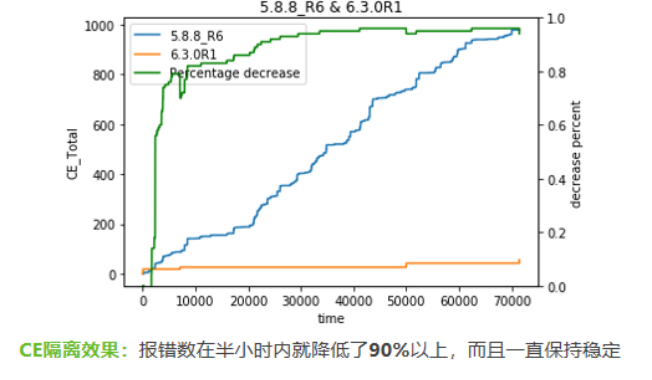
CE隔离效果
资源预测
资源预测告警可以展示即将资源耗尽的服务器组、资源池、虚拟机。

CPU、内存、存储预测中,可以看到历史数据和未来趋势,以及剩余安全容量、预计多少天后将超过安全容量阈值、以及建议扩容容量。
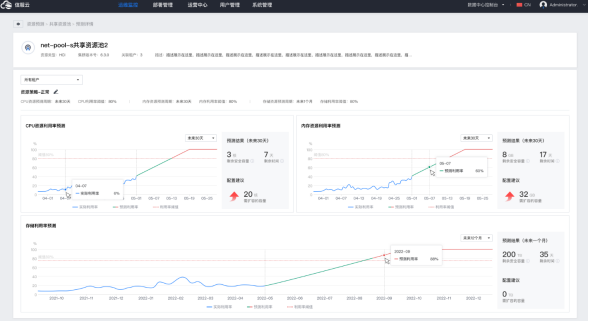
当资源过剩时,也可基于智能算法对闲置虚拟机进行识别,回收对应的资源池或服务器资源。
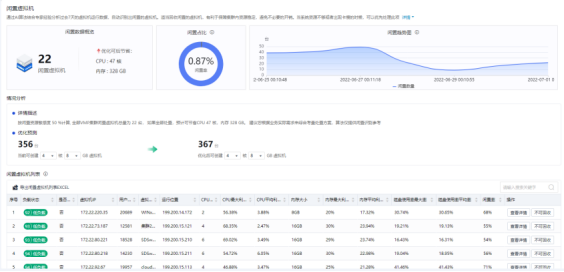
识别闲置虚拟机
未来,在故障预测、分析与自愈上,该系统将完善各个业务场景的故障预测分析工作,根据专家经验的处置决策树设置自动处置闭环,并基于强化学习优化处置策略。
在识别业务特征上,将识别包含业务性能与不同资源的敏感度、业务特定的最佳实践方案等。使得业务在故障、亚健康等场景下,能够准确、快速地定位问题,比如帮助后端运维提前感知问题,及时更换硬件,避免因硬件问题引发的业务中断。
另外,在硬件亚健康集群的分析上,系统可以提供集群版本升级建议,以及DRS各类调度优化能力,可以更加准确地针对性地对业务进行优化,一定程度上避免资源浪费。
还可根据托管云硬件故障情况分析硬件故障率,硬件故障变化趋势等信息,为硬件导入选型提供事实举证,并结合硬件故障率在数据中心的分布,给仓储备件的分配提供优化建议。
在托管云上,借助于业务全生命周期持续性保障系统,用户可以直观地了解当前业务运行健康程度与面临的风险大小,提前预测风险,并及时处置,从而实现业务的稳定连续运行。